On the use of LLM (“AI”) in security decisions
- Albert Zenkoff
- 2026-03-29
What will happen if we keep using Large Language Models as the basis of decisions, especially in a field like security? Would taking the statistically average decision from this moment on, at every step, lead to a decay of decision correctness over time, or would it stay stable?
The question sits at the intersection of decision theory, statistics, and ergodicity. The short answer is: decay, almost inevitably, and for several reinforcing reasons.
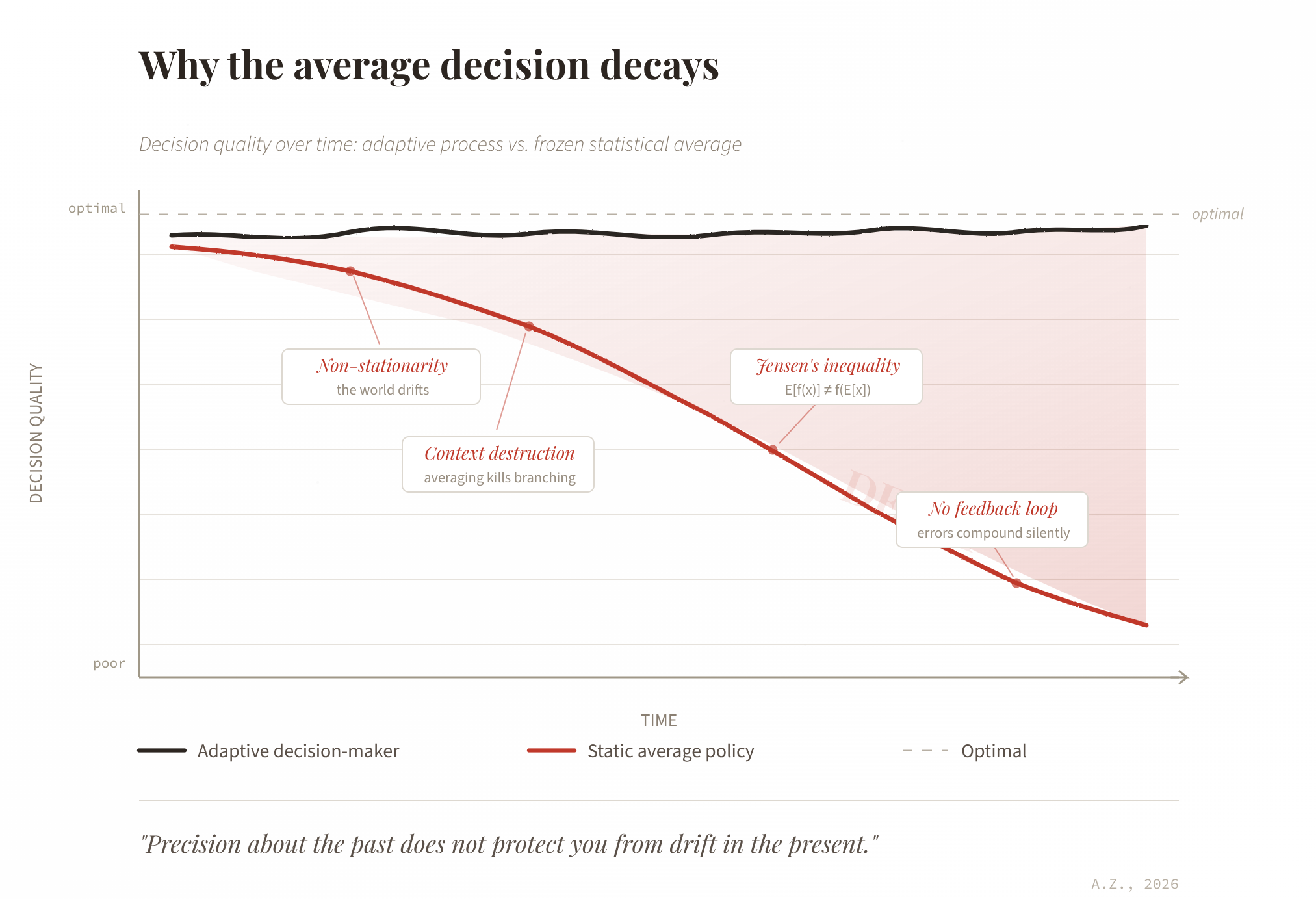
Non-stationarity is the dominant force. The world drifts, markets shift, relationships evolve, technology reshapes the landscape under your feet. The historical average decision was optimal, or at least adequate, for the distribution of situations as they existed at the time of observation. The moment you freeze your policy to “always take the average,” you anchor yourself to a past that is already receding. The longer you run on that fixed average, the more misaligned it becomes with the current environment. In security, where the adversary actively works to invalidate your assumptions, this misalignment accumulates faster than in most other domains.
Averaging destroys context-sensitivity, and this is where the damage becomes structural even without environmental drift. Good decisions are typically conditional: you do X when you observe A, and Y when you observe B. Collapse all of those into a single average and you lose the branching logic that made each individual decision correct in its context. Consider the case where your two correct responses are “accelerate” and “brake,” the average of those two is “do nothing,” which is the worst option in both situations. This holds true even in a perfectly stationary environment, because the problem is not that the average is outdated but that it never captured the decision structure to begin with.
Non-linear payoffs compound the problem further. By Jensen’s inequality, when the payoff function is concave or convex, the payoff of the average decision is not equal to the average payoff of the individual decisions. In many real domains, finance, health, security, engineering, the payoff functions are sharply non-linear, small deviations from the correct call carry disproportionate costs. The average smooths away the precision you need most at exactly the points where the stakes are highest.
The absence of a feedback loop removes the last safety net. A living decision-maker adapts: they observe a bad outcome, update their model, adjust the next decision. A frozen average policy has no such mechanism. Errors accumulate without correction, and in path-dependent systems, where today’s outcome constrains tomorrow’s available options, those errors compound. You do not merely fall behind, you fall behind in a way that makes recovery progressively harder.
There is one theoretical exception: a hypothetical environment that is perfectly stationary, where decisions are context-independent, payoffs are linear, and there is no path-dependence. In that narrow case, the sample mean would converge to the true optimum and remain stable. That describes almost no real decision domain, and it certainly does not describe security, where the entire game is played on shifting ground.
The decay, then, is not a risk to be mitigated. It is a structural certainty, the inevitable cost of substituting a static summary statistic for an adaptive process. The statistical significance of your historical sample gives you a precise estimate of what was correct before, but precision about the past does not protect you from drift in the present.