Technology
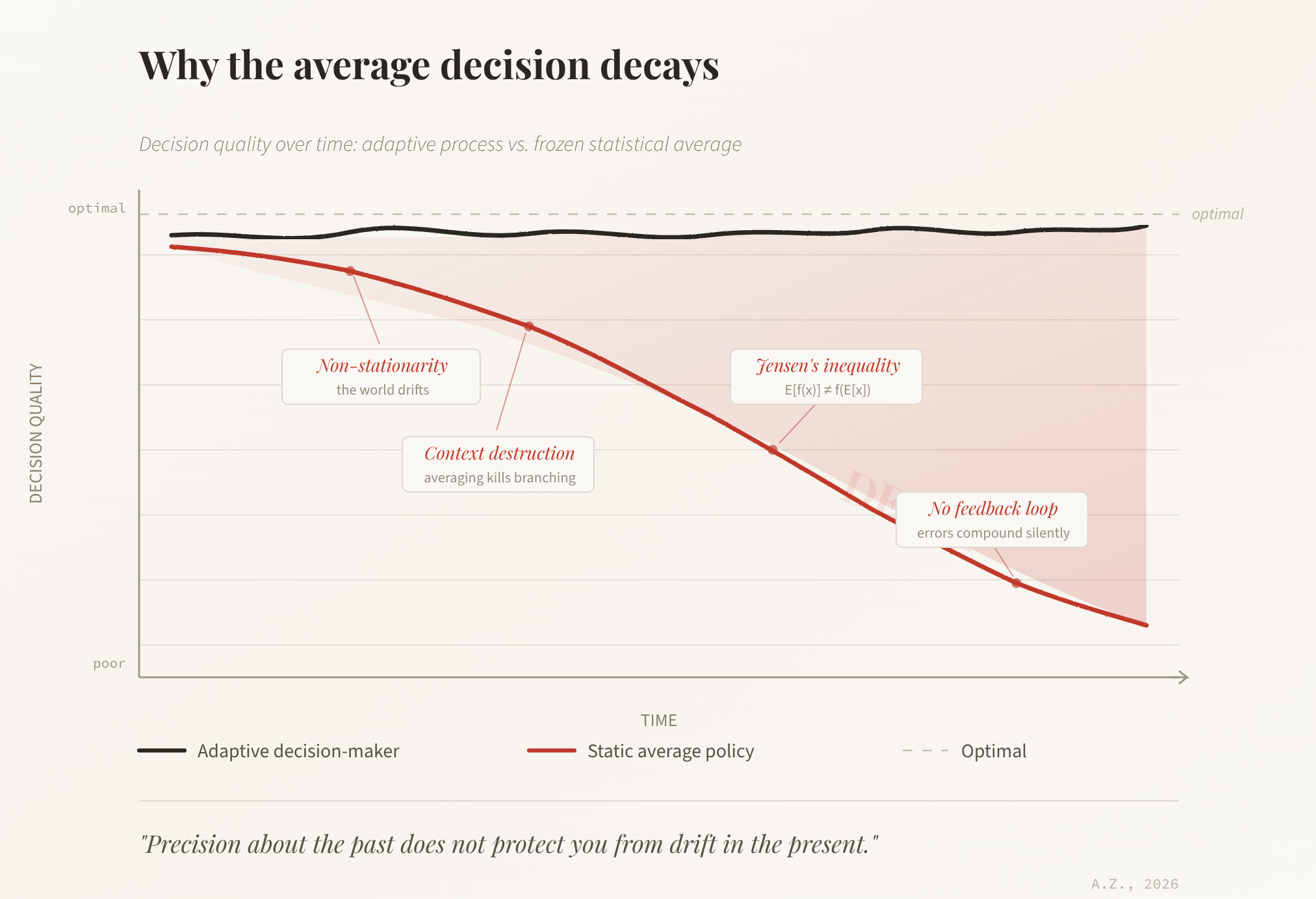
On the use of LLM (“AI”) in security decisions
- Albert Zenkoff
- 2026-03-29
- Technology, Artificial Intelligence, LLM, long-term view, perspective, philosophy, security, technology
What will happen if we keep using Large Language Models as the basis of decisions, especially in a field like security? Would taking the statistically average decision from this moment on, at every step, lead to a decay of decision correctness over time, or would it stay stable? The question sits at the intersection of ...
Read More
AI Software Design Security and Language Choice
- Albert Zenkoff
- 2025-11-30
- Technology, Development, technology
Or, rather, the quality of the Artificial Intelligence (AI) generated software in general but it goes for security as well, naturally, since security and quality are but the two sides of the same coin. Software engineers happily embraced the wonderful possibility of being able to program in a natural language – describing the task to ...
Read More
Worst languages for software security
- Albert Zenkoff
- 2016-01-19
- Technology, C/C++, Development, Java, languages, misleading, OWASP, philosophy, problem, quality, security promise, vulnerability, web application
I was sent an article about program languages that generate most security bugs in software today. The article seemed to refer to a report by Veracode, a company I know well, to discuss what software security problems are out there in applications written in different languages. That is an excellent question and a very interesting ...
Read More
Passwords and other secrets in source code
- Albert Zenkoff
- 2015-03-30
- Technology, certificates, code scanner, Development, embed, keys, secrets, source code
Secrets are bad. Secrets in source code are an order of magnitude worse. Secrets are difficult to protect. Every attacker goes after the secrets and we must protect our secrets against all of them. The secrets are the valuable part of our software and that’s why they are bad – they represent an area of ...
Read More
House key versus user authentication
- Albert Zenkoff
- 2015-03-05
- Technology, authentication, authorization, difference, house key, key, protection
I got an interesting question regarding the technologies we use for authentication that I will discuss here. The gist of the question is that we try to go all out on the technologies we use for the authentication, even trying unsuitable technologies like biometrics, while, on the other hand, we still use fairly simple keys ...
Read More
About the so-called “uncertainty principle of new technology”
- Albert Zenkoff
- 2015-01-08
- Technology, arete, beauty, Collingridge Dilemma, engineering, harmony, inherently hard, new technology, quality, scientific discovery, security, society
It has been stated that the new technology possesses an inherent characteristic that makes it hard to secure. This characteristic is articulated by David Collingridge in what many would like to see accepted axiomatically and even call it the “Collingridge Dilemma” to underscore its immutability: That, when a technology is new (and therefore its spread ...
Read More
Heartbleed? That’s nothing. Here comes Microsoft SChannel!
- Albert Zenkoff
- 2014-11-13
- Technology, attack, critical, HeartBleed, library, Microsoft Secure Channel, no mitigation, no workaround, patch, remote, remote code execution, SChannel, vulnerability, WinBleed
The lot of hype around the so-called “Heartbleed” vulnerability in open-source cryptographic library OpenSSL was not really justified. Yes, many servers were affected but the vulnerability was quickly patched and it was only an information disclosure vulnerability. It could not be used to break into the servers directly. Now we have Microsoft Secure Channel library ...
Read More
More on WordPress xmlrpc denial of service attacks
- Albert Zenkoff
- 2014-09-08
- Technology, apache, attack, conditions, denial of service, DOS, protection, rewrite, rewrite_mod, rules, service, user agent, WordPress, xmlrpc
The attacks on WordPress using xmlrpc.php service are rather common. I already mentioned that you could filter out unwanted user-agents using the redirect capability of Apache. That would, however, take care only of obvious cases, where you see that this particular user-agent could not possibly be your reader. What do we do if the user-agent ...
Read More
Mitigating Denial of Service attacks to WordPress xmlrpc
- Albert Zenkoff
- 2014-07-14
- Technology, attack, botnet, DDOS, denial of service, htaccess, mitigation, redirect, server, user agent
I have attracted attention, apparently. My website is under a Distributed Denial of Service (DDOS) attack by a botnet for the last week. I am flattered, of course, but I could live without a DDOS, frankly. The requests go to xmlrpc.php every second or two from a different IP address from around the world: POST ...
Read More
Over-engineering
- Albert Zenkoff
- 2014-04-13
- Technology, bugs, code size, coding techniques, complexity, keep it simple, kiss, maintainability, management, over-engineering, overengineering, show off, technology
Causes for security problems are legion. One of the high pertinence problems in software development is called “over-engineering” – creation of over-complicated design or over-complicated code not justified by the complexity of the task at hand. Often it comes as a result of the designer’s desire to show off, to demonstrate the knowledge of all ...
Read More